hydrox
dive deeper into your code
1 Introduction
1.1 Overview
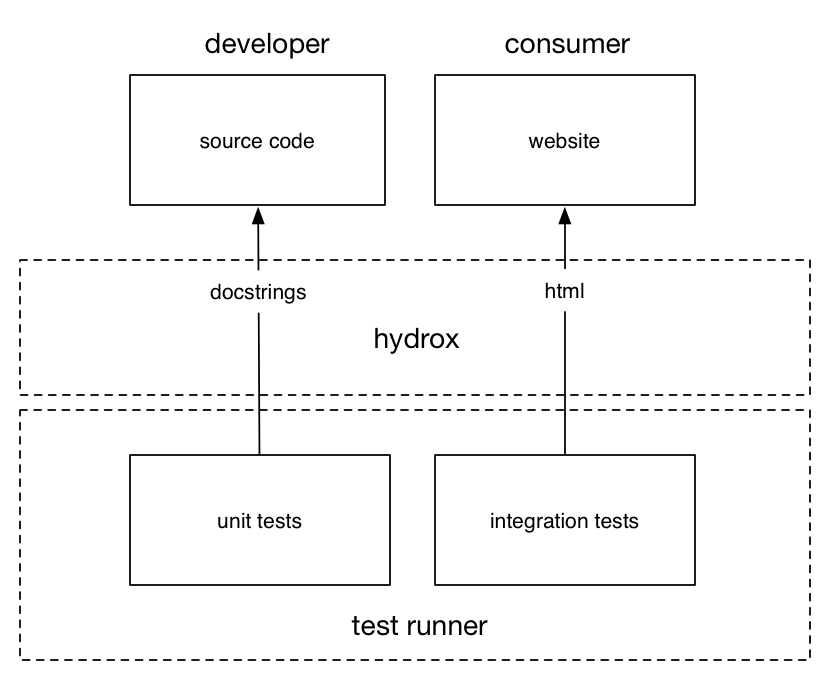
hydrox assists in the transmission of knowledge around a clojure project, providing in-repl management of documentation, docstrings and metadata through the reuse/repurposing of test code. Facillitating the creation of 'documentation that we can run', the tool allows for a design-orientated workflow for the programming process, blurring the boundaries between design, development, testing and documentation.
1.2 Installation
1.2.1 Standard
In your project.clj, add hydrox to the [:profiles :dev :dependencies] entry:
(defproject ...
...
:profiles {:dev {:dependencies [...
[helpshift/hydrox "0.1.15"]
...]}}
...)
All functionality is the hydrox.core namespace:
1.2.2 Vinyasa
A better experience can be obtained by using vinyasa and editing your ~/.lein/profiles.clj to inject all hydrox vars into the . namespace:
{:user
{:plugins [...]
:dependencies [[im.chit/vinyasa.inject "0.3.4"]
[helpshift/hydrox "0.1.15"]]
:injections
[(require '[vinyasa.inject :as inject])
(inject/in [hydrox.core dive surface generate-docs
import-docstring purge-docstring])]}}
Functions can then be used like this within the repl:
1.3 Motivation
Programming is a very precise art form. Programming mistakes, especially the little ones, can result in dire consequences and much wasted time. We therefore use tools such as debuggers, type checkers and test frameworks to make our coding lives easier and our source code correct.
Documentation is the programmers' means of communicating how to use or build upon a library, usually to a larger audience of peers. This means that any mistakes in the documentation results in wasted time for all involved. Therefore any mistake in documentation can have a greater effect than a mistake in source code because it wastes everybody's time.
There are various tools for documentation like latex, wiki and markdown. However, none address the issue that code examples in the documentation are not checked for correctness. hydrox attempts to bridge the gap between writing tests and writing documentation by introducing the following features:
1.3.1 Features
The features are:
- To generate
.htmldocumentation from a.cljtest file. - Management of function docstrings and metadata through tests
- Express documentation elements as clojure datastructures.
- Render code, clojure.test and midje test cases as examples.
- Latex-like numbering and linking facilities.
1.3.2 Benefits
In this way, the project benefits in multiple ways:
- All documentation errors can be eliminated.
- Removes the need to cut and copy test examples into a readme file.
1.3.3 Improvements
The precessor of hydrox was midje-doc, and it provided very much the same functionalities as the current hydrox implementation. Whilst midje-doc was built primarily as a leiningen plugin, it was found that the tool was more effective for the development when used within the repl.
There are significant improvements of hydrox over midje-doc including:
- Declarative source code traversal using jai
- Extensible micropass pipeline for compilation and linking
- Customisable templates system for html documentataion
- Code-diffing mechanism for efficient management of filesystem changes
1.4 Literate Programming
The phrase 'Literate Programming' has been bandied around alot lately. The main idea is that the code is written in a way that allows both a machine and a person to understand what is going on. Most seem to agree that it is a great idea. The reuse factor of not writing seperate documentation alone brings great excitement to many developers. However, we must understand that methods of effective communication to humans and machines are very different:
Communication to Machines are usually linear and based on a specific set of instructions. First Do This, Then Do That.... Machines don't really care what the code does. It just executes whatever code it has been given. The main importance of establishing that a program is correct is to give it a set of verifible input/output responses and see if it behaves a certain way.
Communication to Humans are usually less procedural and more relational. We wish to be engaged, inspired and taught, not given a sequence of instructions that each break down to even smaller sequences. The best documentation are usally seperated into logical sections like an overview, table of contents, list of figures, chapters, sections and subsections. There are text, code, pictures, even sound and video. Documentation structure resemble trees, with links between content that connect related topics and content. They do not resemble program code and therefore should be created independently of the machine code itself.
2 Facillitating Communication
2.1 Code as Communication
The primary reason for building hydrox was to simplify the communication process across a clojure project. In general, the programming process can be seen as a set of different communication types with the developer acting as the facillitator for the following:
- with the machine telling it what to do (code)
- with the machine, verifying that it has done it's job (unit and integration tests)
- with themselves/other developers, telling them how to use the function (unit tests and docstrings)
- with the end user, telling them how to do it (design/integration documentation)
Notice that with the 4 points listed, there happens to be some overlap between 2 and 3 (unit tests) as well as 2 and 4 (integration). We can categorise the overlap as follows:
- unit/function level documentation (intended for communicating with a machine/developer)
- design/integration level documentation (intended for communicating with a consumer)
This overlap is very important because this is the one area where repetitive activities occur. hydrox helps limit this repetition through automation of the documentation workflow.
2.2 Functional Level Documentation
The best description for our functions are not found in source files but in the test files. Tests are potentially the best documentation because they provide information about what a function outputs, what inputs it accepts and what exceptions it throws. The best place to display functional level documentation is in the docstring as the clojure ecosystem has amazing support for the uses of docstings in tools such as cider, cursive, codox, grimoire and many others.
Lets discuss the problem with the following piece of code:
e.2.1 - split-string source
Technically, everything is fine except that the docstring is pretty much useless. Instead of writing vague phrases, we write our test as follows (usually in another file):
e.2.2 - split-string tests
It can be seen that test cases provides a much better explaination for split-string than the source docstring because any developer can immediately tell what inputs the function accepts and what outputs it returns. In this case, hydrox provides the function import-docstring to turn a test into a docstring and then deliver it back into the source code.
2.2.1 Import Docstring
The following hydrox calls:
Results in the split-string function looking like this:
e.2.3 - split-string after import-docstring
It is possible to target the docstring of a source file when the test code is in another file is due to the ^{:refer documentation.hydrox-guide/split-string :added "0.1"} metadata that was included as part of the test. The other call to dive was needed to link the source and test files. It only needs to called once and will be explained in a later section.
2.2.2 Purge Docstring
Sometimes, it's better to just concentrate on the function itself for more clarity, in this case, the purge-docstring function is really useful:
Results in the split-string function looking like this, having no docstring or metadata:
e.2.4 - split-string after purge-docstring
To bring the docstring and metadata back again, just make another call to import-docstring. With the tests for split-string in place, it is easy to manage metadata and docstrings. Having the information within the test files decreases source code clutter and we can import/purge them as needed, dependending upon the situation.
2.3 Design Level Documentation
Documentation at the design level requires more visual elements than documentation at the function level. hydrox can generate html output based on a .clj file and a template. This requires some configuration and so the following is placed in the project.clj map.
The :documentation key in defproject specifies which files to use as entry points to use for html generation. A sample can be seen below:
A pretty looking html document can be generated by running generate-docs:
The :output entry specifies the directory that files are rendered to, :template' specifies the files that are needed to generate the file. The current template will generate the same as the current documentation.
3 API Reference
3.1 The Basics
3.1.1 elements
Elements are constructed using a tag and a map contained within double square brackets. Elements tags have been inspired from latex:
Clojure strings are treated as paragraph elements whilst clojure forms are treated as code elements.fact and comment forms are also considered code elements. Elements will be described in detail in their respective sections.3.1.2 attributes
Attribute add additional metadata to elements. They are written as a single hashmap within double square brackets. Attributes mean nothing by themselves. They change the properties of elements directly after them.
Multiple attributes can be stacked to modify an element:
produces the following shell code:
3.2 Sectioning Elements
Sectioning elements are taken from latex and allow the document to be organised into logical sections. From highest to lowest order of priority, they are: :chapter, section, subsection and :subsubsection, giving four levels of organisation.
The numbering for elements are generated in sequencial order: (1, 2, 3 ... etc) and a tag can be generated from the title or specified for creating links within the document. :chapter, section and subsection elements are list in the table of contents using tags.
For example, I wish to write a chapter about animals and have organised content into categories shown below.
It is very straight forward to turn this into sectioning elements which will then generate the sectioning numbers for different categories
The sections will be automatically numbered as show below:
3.3 Content Elements
Content elements include :paragraph, :image, and file elements.
3.3.1 :paragraph
Paragraph elements should make up the bulk of the documentation. They can be written as an element or in the usual case, as a string. The string is markdown with templating - so that chapter, section, code and image numbers can be referred to by their tags.
e.3.2 - Paragraph Element
e.3.3 - Paragraph String
e.3.4 - Markdown String
3.3.2 :image
The :image element embeds an image as a figure within the document. It is numbered and can be tagged for easy reference. The code example produces the image seen in Figure 2:
3.3.3 :file
The :file element allows inclusion of other files into the document. It is useful for breaking up a document into managable chunks. A file element require that the :src attribute be specified. A high-level view of a document can thus be achieved, making the source more readable. This is similar to the include element in latex.
3.4 Code Elements
Code displayed in documentation are of a few types:
- Code that needs to be run (normal clojure code)
- Code that needs verification taking input and showing output. (midje fact)
- Code that should not be run (namespace declaration examples)
- Code that is part of the library's tests or source definition
- Code in other languages
The different types of code can be defined so that code examples render properly using a variety of methods
3.4.1 normal s-expressions
Normal s-expressions are rendered as is. Attributes can be added for grouping purposes. The source code shown below
e.3.6 - seperating code blocks through attributes
renders the following outputs:
3.4.2 test forms
Documentation examples put in facts forms allows the code to be verified for correctness using lein midje. Document element notation still be rendered except before and after the midje arrows (=>). Consecutive code within a fact form will stacked as one common code block.
The source form:
e.3.9 - Facts Form Source
Renders the following output:
3.4.3 fact form
For an entire block to be embedded in code, use the fact form. The source form:
e.3.12 - Fact Form Source
Renders the following output:
e.3.13 - Fact Form Output
3.4.4 comments
Comments are clojure's built-in method of displaying non-running code and so this mechanisim is used in clojure for displaying code that should not be run, but still requires display. Code can still output without interferring with code or tests.
3.4.5 reference
Sometimes we wish to refer to source/test code that is already in our library, we can do this using the :reference directive:
e.3.16 - source of hydrox.core/dive
We can refer to tests as well by changing the :mode to :docs (by default it is :source):
3.4.6 code
The most generic way of displaying code is with the :code tag. It is useful when code in other languages are required to be in the documentation.
3.4.6.1 Python Example
The source and outputs are listed below:
3.4.6.2 Ruby Example
The source and outputs are listed below:
4 A Bug's Life
4.1 Version One
A new clojure project is created.
A very useful function add-5 has been defined:
e.4.1 - src/fami/operations.clj
And the corresponding tests specified:
e.4.2 - src/fami/test-operations.clj
There are additional entries for the operation in the readme as well as also being scattered around in various other documents.
e.4.3 - readme.md, operations.md
This version of this library has been released as version 1.0
4.2 Version Two
The library is super successful with many users. The code undergoes refactoring and it is decided that the original add-5 is too powerful and so it must be muted to only accept one argument. An additional function add-5-multi is used to make explicit that the function is taking multiple arguments.
e.4.4 - src/fami/operations.clj - v2
The tests throw an exception but are quickly fixed:
e.4.5 - src/fami/test-operations.clj
This version of this library has been released as version 2.0
4.3 The Bug Surfaces
Although the tests are correct, the documentation is not. Anyone using this library can potentially have the clojure.lang.ArityException bug if they carefully followed instructions in the documentation.
This is a trival example of a much greater problem. When a project begins to evolve and codebase begins to change, the documentation then becomes incorrect. Although source and test code can be isolated through testing, fixing documentation is a miserable and futile exercise of cut and paste. With no real tool to check whether code is still valid, the documentation become less and less correct until all the examples have to be rechecked and the documention rewritten.
Then the codebase changes again ...
Once the library has been release to the world and people have already started using it, there is no taking it back. Bugs propagate through miscommunication. Miscommunication with machines can usually be contained and fixed. Miscommunication with people becomes potentially more difficult to contain.
This simple scenario highlights the problem that developers have when updating documentation. When we cannot prove that our documentation is correct, then the cost of fixing out of date documentation becomes bigger and bigger as time progresses. With hydrox this process just became much more cost effective.